News
2023/08/18 NePu accepted @GCPR2023 (Nectar Track).
2023/03/09 Further coverage of this work at Innovation Origins.
Abstract
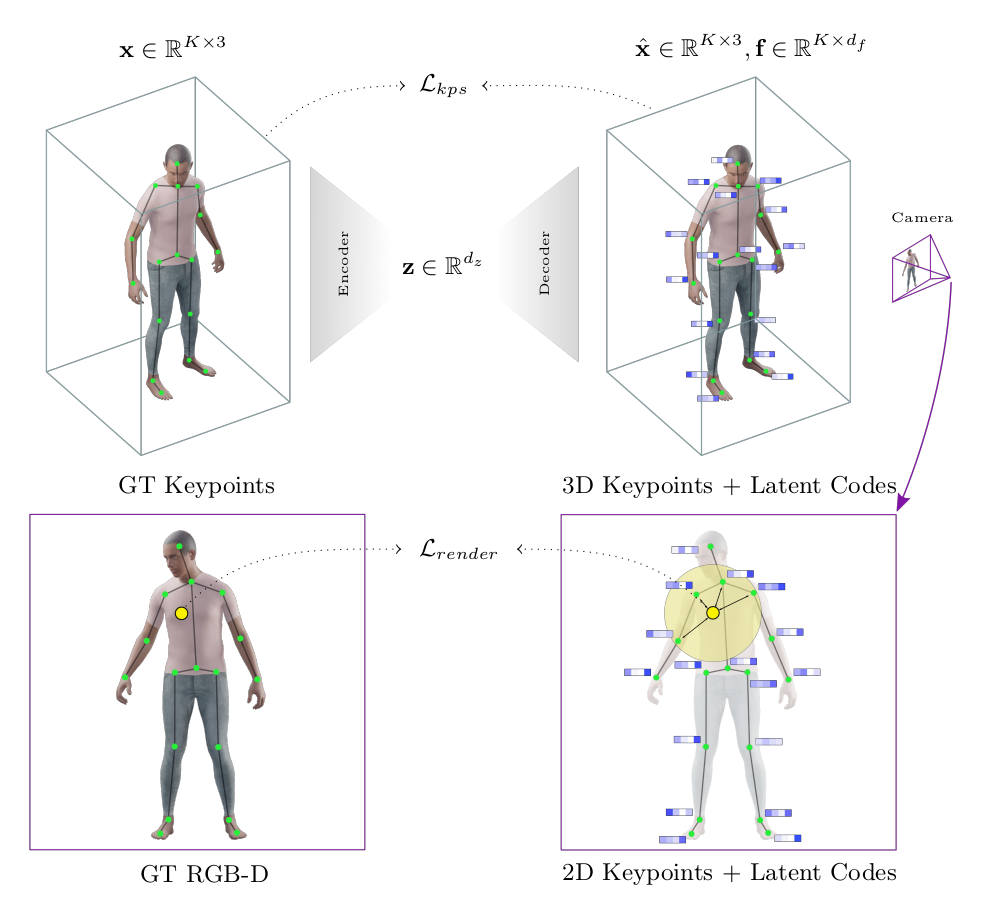
We introduce Neural Puppeteer, an efficient neural rendering pipeline for articulated shapes. By inverse rendering, we can predict 3D keypoints from multi-view 2D silhouettes alone, without requiring texture information. Furthermore, we can easily predict 3D keypoints of the same class of shapes with one and the same trained model and generalize more easily from training with synthetic data which we demonstrate by successfully applying zero-shot synthetic to real-world experiments. We demonstrate the flexibility of our method by fitting models to synthetic videos of different animals and a human, and achieve quantitative results which outperform our baselines. Our method uses 3D keypoints in conjunction with individual local feature vectors and a global latent code to allow for an efficient representation of time-varying and articulated shapes such as humans and animals. In contrast to previous work, we do not perform reconstruction in the 3D domain, but project the 3D features into 2D cameras and perform reconstruction of 2D RGB-D images from these projected features, which is significantly faster than volumetric rendering. Our synthetic dataset will be publicly available, to further develop the evolving field of animal pose and shape reconstruction.
An Introduction to Neural Puppeteer
Additional Results
Novel Pose and View Synthesis
Our network was trained only on individual poses. We apply our rendering pipeline to keypoints from motion captured data from the AMASS dataset.
One failure case comes up if the animation is far from the trained poses, as is the case with this crawling animation. There are problems with the mask in occluded areas as well as artifacts towards the edge of the reconstruction region.
Latent Space Interpolation
Each video shows the linear interpolation between different pose encodings from the test set.
View Consistency
Each video shows a single pose rendererd from a camera circling around the subjects at different heights.
Real World
The animation shows the process of pose optimization from the initialization to the final pose given the silhouette.
Cite us
@inproceedings{giewald2022nepu,
author={Giebenhain, Simon and Waldmann, Urs and Johannsen, Ole and Goldluecke, Bastian},
title={Neural Puppeteer: Keypoint-Based Neural Rendering of Dynamic Shapes},
booktitle={Proceedings of the Asian Conference on Computer Vision (ACCV)},
month={December},
year={2022},
pages={2830-2847}
}